There are several reputable reviewers that present runtime graphs showing the integrated OTF luminous flux as a function of time. The data is valuable and appreciated as most of us can’t do that.
Understandably, given different setups, calibration, or even the individual sample of the flashlight being reviewed those measurements will inevitably vary. But by how much and how likely it is that the reviewers have systematic bias?
To have a glimpse, I looked at 4 reviews (@tactical_grizzly, @zeroair, @1Lumen, and @PiercingTheDarkness) of the same flashlight model - Wurkkos TS23. I tried to extract the lumens values at 4 different intensity levels from each of the reviews the best I could. I summarised it in the graph below, which is an extension of the standard Bland-Altman plot, but plotting the difference of the value reported by each reviewer at each intensity level (after it becomes constant) vs. the average of all four (since we don’t know the ‘true’ value).
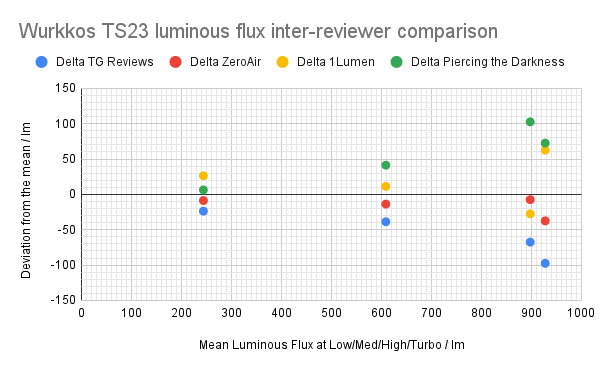
Whether those differences are consequential or not is debatable. Overall, the relative difference from the mean are within around 10% of the mean (but more if you compare the differences between individual reviewers rather than the difference from the mean), which is what the reviewers usually claim.
So for example, at the high level or some 900 lm average, the individual reports may vary from about 800 to 1000 lm - about 200 lm or some 20% difference, which is not trivial, albeit unlikely highly visually significant.
Interestingly, there seems to be a systematic bias involved - some reviewers report values generally higher (or lower) than others across the levels.
A word of caution on interpreting the plot above: since nobody knows what the true lumens are, the arbitrary baseline (zero line) is taken as the arithmetic mean of all four attempts at measuring the true value (at each level). The individual measurements may straddle the true values or, just as likely, can be all systematically too high or too low. By extension, it means that being close to the zero line is immaterial to assessing the accuracy of a reviewer - without a standard there is no way of assessing which dataset/reviewer is most accurate - one can only quantify how different they are from one another.
